扫码加好友
数字人SyncTalk解压即用N卡整合版 240607 (GITHUB版本为:240528)
● 介绍(这些都不需要打开,只是介绍。整合包解压即用)
开源地址:https://github.com/ZiqiaoPeng/SyncTalk
下载地址:https://51qpm.66868344.cn/synctalk/
● 亮点
○ 支持视频的真3D数字人
○ 支持训练
○ 在素材优秀训练得当前提下,是目前论坛上限最高的数字人。
● 使用条件
○ 操作系统:Win10、Win11
○ 最低显卡:英伟达显卡(N卡)1050 4G
○ VS、CUDA:不需要、整合包解压即用。
○ CUDA版本:虽然不需要额外安装CUDA,但要确保你的显卡驱动正常,且驱动版本不能太旧,要求驱动里CUDA版本>=11.8。
● 更新
[2023-11-30] 更新arXiv论文。
[2024-03-04] 代码和预训练模型发布。
[2024-03-22] Google Colab 笔记本发布。
[2024-04-14] 添加 Windows 支持。
[2024-04-28] 预处理代码发布。
[2024-04-29] 修复音频编码器、混合形状捕获和人脸跟踪器的 bug。
[2024-05-03] 尝试将 NeRF 替换为高斯 Splatting。代码: GS-SyncTalk
[2024-05-24] 引入躯干训练修复双下巴。
● 免责声明
此软件仅供娱乐、不可用于视频欺骗、人脸识别等一切违反法律的欺诈行为。若有此行为是用户个人行为。与资源发布者无关。
● 使用声明
此程序为开源项目,本程序由圈圈AI吧(ooai8.com)整合修改升级,【解压即用】、【无需授权】、【不限机器】、【不限次数】、【离线运行】 。软件只要下载到您手上,就可以永久使用。
注册成功后可直接获得论坛积分。若积分不够,可以通过登录、签到、发帖等日常操作免费获取。通常发几个帖子签到等,就可以获得足够积分下载。此外打赏作者可快速获得积分。
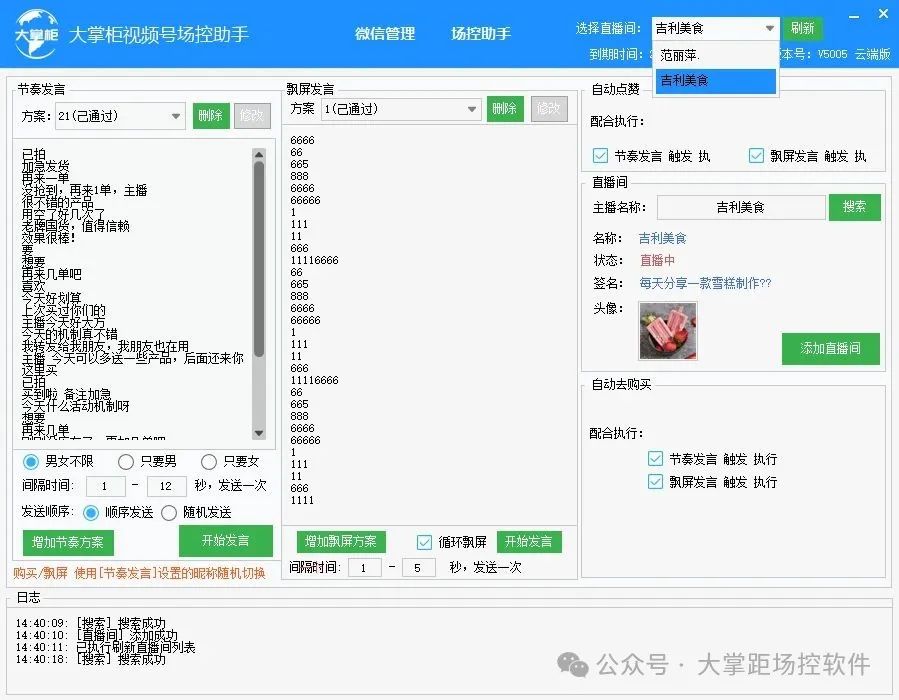
● 数据集制作
○ 首先准备一个MP4格式的视频,要求视频必须为 25FPS ,所有帧都包含说话的人脸。分辨率应约为 512 ×512,持续时间约为 4-5 分钟 。
以上要求为官网作者提供,UP尝试使用40秒的视频作为素材依旧可以成功训练并推理,但是效果欠佳。建议以官方要求为主。
想了解更多可查看官方主页:https://github.com/ZiqiaoPeng/SyncTalk
○ 修改视频文件名,必须是英文数字下划线组合,禁止使用特殊符合或中文,例如:May、Jack、Tom、Tina等,后缀名为mp4
○ 将视频放在整合包内/data/文件名/文件名.mp4。假设你取名为:Trump 并假设你整合包放在D盘根目录,那么视频的完整地址是:
整合包根目录/data/Trump/Trump.mp4 (整合包目录不要带有任何中文或空格,不要套层级太多,推荐放到磁盘根目录)
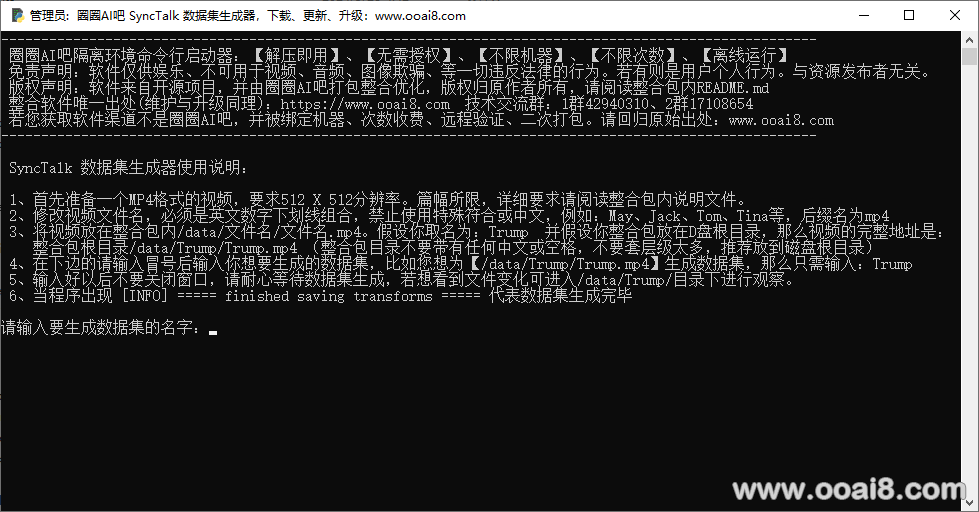
○ 打开【数据集生成器.exe】在下边的请输入冒号后输入你想要生成的数据集,比如您想为【/data/Trump/Trump.mp4】生成数据集,那么只需输入:Trump
○ 输入好以后不要关闭窗口,请耐心等待数据集生成,若想看到文件变化可进入/data/Trump/目录下进行观察。
○ 当程序出现 [INFO] ===== finished saving transforms ===== 代表数据集生成完毕
○ 以上为默认的数据集生成方式,假若你想生成deepspeech方式的数据集,需要在上述步骤完成后把里边的aud.wav转换成成NPY文件。
具体操作方法是打开【音频转NPY工具.exe】,输入您的数据集里aud.wav路径,例如:/data/Trump/Trump.mp4
● 训练 ○ 假定您第一步在制作数据集的时候,启用的名称是【May】下文以此为例详细介绍训练命令 ○ 打开【命令行调试器.exe】输入以下命令:
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model ave
注意:若您的名称不是May请替换命令中的May,一共两处。前边的 data/May 是您在第一步生成好的数据集目录。 后边的 model/trial_may 是训练后的生成目录,训练完成模型保存到这里。 例子:假设您第一步数据集名称为May,那么训练的命令就是:(以下三种方式任选其一)
○ ave方式:(适用于具有准确口型同步和大嘴唇运动的角色)
# python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model ave``# python main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model ave
○ deepspeech方式:(如果您的训练结果显示嘴唇抖动,请尝试使用 deepspeech 或 hubert 模型作为音频特征编码器。)
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model deepspeech``python main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model deepspeech
○ hubert方式:(如果您的训练结果显示嘴唇抖动,请尝试使用 deepspeech 或 hubert 模型作为音频特征编码器。)
python main.py data/May --workspace model/trial_may -O --iters 60000 --asr_model hubertpython main.py data/May --workspace model/trial_may -O --iters 100000 --finetune_lips --patch_size 64 --asr_model hubert
○ 训练时间比较长,请耐心等待,提供一个参考,UP用案例视频4分多钟长,大约不到3个小时,不同机器配置有差异仅供参考。
● 推理 ○ 整合包自带训练好的May模型,若未经过上边两步,可直接用训练好的May模型进行推理,注意:一个模型对应一个视频,以此推理效果也只是案例视频的数字人。 ○ 推理自己的数字人,首选确保完成了上边的两步:【数据集制作】、【训练】。 ○ 假定您训练好的模型为:May,那么您的推理代码为: ○ ave方式:
# python main.py data/May --workspace model/trial_may -O --test --test_train --asr_model ave --portrait --aud ./inputs/audio.wav
○ deepspeech方式: 注意,此种方式需要将你的音频文件转换为NPY格式,可以使用整合版内的【音频转NPY工具.exe】工具。
# python main.py data/May --workspace model/trial_may -O --test --test_train --asr_model ave --portrait --aud ./inputs/audio_ds.npy
命令解释: python main.py data/May 这是您第一步生成数据集的位置。 -workspace model/trial_jack 这是您第二步训练好模型的位置。 -aud ./inputs/audio.wav 这是您自己的音频路径,可以是相对路径,也可以是绝对路径,使用时可以自定义文件名,路径对应正确即可,注意音频不能用中文命名。
○ 同样打开【命令行调试器.exe】输入您的推理命令。
配套教学视频:1、推理:https://www.bilibili.com/video/BV1Un4y1Q7YW
配套教学视频:2、数据集:https://www.bilibili.com/video/BV1Ni421e7JU
配套教学视频:3、训练:https://www.bilibili.com/video/BV1ks421u74m
配套教学视频:4、训练2:https://www.bilibili.com/video/BV13s421M7mp
配套教学视频:5、DS方式: __https://www.bilibili.com/video/BV1Dw4m1e7fP
配套教学视频:6、DS效果展示:https://www.bilibili.com/video/BV181421C7DF
配套教学视频:7、Hubert效果展示:**https://www.bilibili.com/video/BV1Fx4y187pg
● 常见错误:
○ 整合包一定要放在非中文目录,且不能有空格和特殊字符,推荐放在磁盘根目录以避免路径过长导致识别障碍。
● 下载必读:若您有意下载,请务必阅读本段内容
○ 此软件为论坛目前第一款可训练 的数字人项目
○ 此软件为真3D 数字人
○ 此软件为视频制作数字人,不支持图片
○ 此软件为高清数字人,脸部区域分辨率为512×512,
○ 官方案例不包含身体。若有贴回身体需求请自行解决,务必须知。
○ 若需要贴回身体也可以尝试将身体一同训练,但视频依旧要保持512X512,动手能力强的可自行尝试。
○ 软件为开源软件,UP所做的是将复杂的依赖关系和模型等资源进行整合。做到了解压即用。离线使用。UP未做任何功能性改动。所以在使用中可参考官方文档进行操作。
○ UP做了些非功能性改动:1、修复BUG若干。2、增加命令行调试器、数据集生成器、NPY生成工具、音频16K工具。
○ UP用案例视频训练和推理效果惊艳,但是在使用自己的素材时效果不佳。在经过反复尝试后,严格安装官网的要求和案例视频做参考,终于达到了和官网案例一样的效果。
以下经验供参考:
素材视频时长建议4-5分钟,最好是连贯的,不够可剪辑拼凑。
素材视频脸部区域占中,比例可以参考案例视频。
推荐使用原生25FPS的,如果是30FPS硬性转换为25FPS效果不好。
如果是50FPS以上的视频,强行转换为25FPS效果还可以。
视频务必使用512X512分辨率,不可自作聪明。
如果以非AVE方式训练推理,需要将音频采样率转换为16000.
○ UP能保证的是,软件可以正常使用、真解压即用、离线使用、整合包完整、数据集生成成功。训练成功,推理成功。
○ 此软件上限极高,但对素材要求也高,需要您有足够的训练和推理经验。UP对软件素材选择,训练技巧,推理技巧还在体验和摸索中,UP可以和用户一起探讨交流,但不代表UP对训练很精通。UP能做到的是视频演示的效果,若您实力足够强大,可训练出比UP更优秀的数字人。UP保证整合包正常使用,并包含官方版本中所带的功能。并为您进行指导。
[ri-alerts color=“primary”]数字人SyncTalk项目完整整合包下载地址[/ri-alerts]
[rihide]链接:https://pan.baidu.com/s/1QKCl06ebgSOjQHEqHQKJtA?pwd=ljte 提取码:ljte[/rihide]

相关推荐